
複数の表記形式のFIが混在するpandas.DataFrameの列から正規表現を用いて各FIを抽出して新たな列を生成する方法
日本では、IPCをベースとしてIPC(国際特許分類)に展開記号及び/又は分冊識別記号を付加する形で日本独自に細展開したFIを使用しているため、FIの表記形式には下記リンク先に記載のように「IPC記号(のみ)」、「IPC記号+分冊識別記号」、「IPC記号+展開記号」又は「IPC記号+展開記号+分冊識別記号」の4種類が存在します。

J-PlatPat(特許情報プラットフォーム)から[CSV出力]でダウンロードしたCSVファイルをpandasを用いてデータ分析する場合に、複数種類のFIを要素とする列から、正規表現を用いて各FIを漏れなく抽出するためにstr.extractall()メソッドが使えます。str.extractall()には引数expandは無く、常にindexがマルチインデックスのpandas.DataFrameを返します。結果は以下のようになります。
df_fi['FI'].head()
0 A61B17/29
1 A61B17/29,A61B5/0245,100@B,A61B5/1455
2 A61B17/29,A61B34/00,A61B90/50
3 A61B1/018,515,A61B1/12,531,A61B17/94,A61B17/29
4 F16H19/02@J,B25J1/02,F16D7/04@A,G05G1/08@B,G05G7/04@Z,G05G7/10@Z,A61B17/29
df_fi_all = df_fi.str.extractall('([A-Z][0-9]+[A-Z][0-9]+/[0-9]+,[0-9]+@[A-Z]|[A-Z][0-9]+[A-Z][0-9]+/[0-9]+,[0-9]+|[A-Z][0-9]+[A-Z][0-9]+/[0-9]+@[A-Z]|[A-Z][0-9]+[A-Z][0-9]+/[0-9]+)')
df_fi_all['FI'].head()
0 0 A61B17/29
1 0 A61B17/29
1 A61B5/0245,100@B
2 A61B5/1455
2 0 A61B17/29
1 A61B34/00
2 A61B90/50
3 0 A61B1/018,515
1 A61B1/12,531
2 A61B17/94
3 A61B17/29
4 0 F16H19/02@J
1 B25J1/02
2 F16D7/04@A
3 G05G1/08@B
4 G05G7/04@Z
5 G05G7/10@Z
6 A61B17/29参考にさせていただいたサイト:
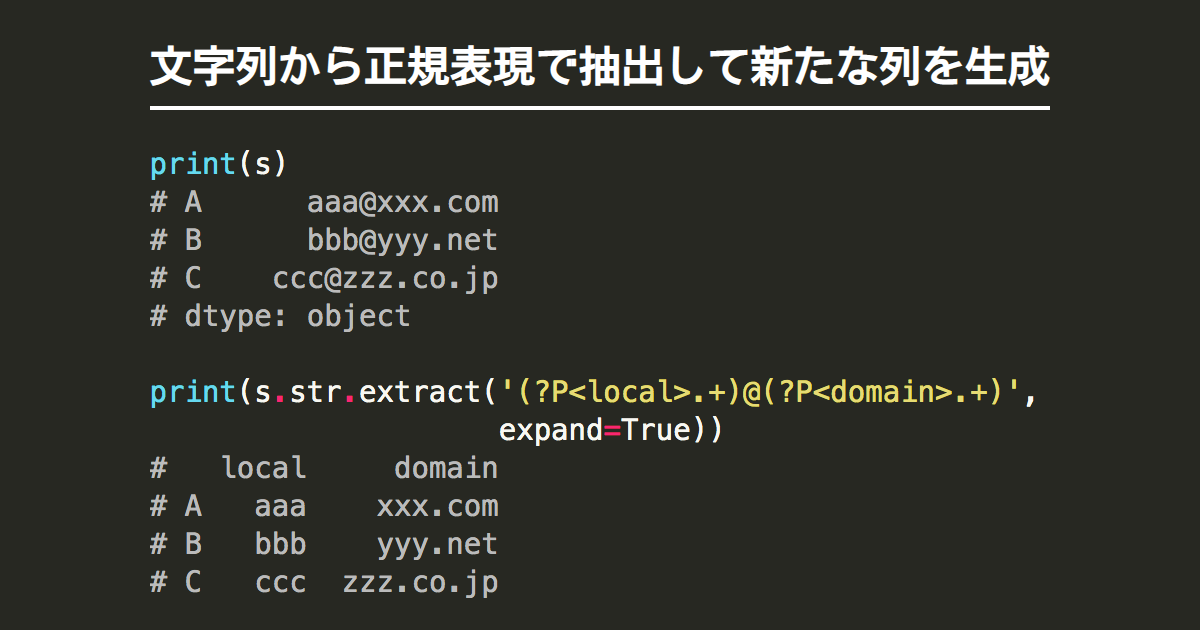
pandasの文字列から正規表現で抽出して新たな列を生成 | note.nkmk.me
文字列を要素とするpandas.DataFrameの列、pandas.Seriesから正規表現で特定の文字列を抽出して新たな列を生成する方法を説明する。 以下の文字列メソッドを使う。 str.extract(): 最初のマッチ部分のみ抽出 ...
note.nkmk.me

re --- 正規表現操作
ソースコード: Lib/re/ このモジュールは Perl に見られる正規表現マッチング操作と同様のものを提供します。 パターンおよび検索される文字列には、Unicode 文字列 ( str) や 8 ビット文字列 ( bytes) を使い...
docs.python.org